Now that SciPy 2020 is over, I would like to share the process I used to create the talk video. The effect was designed to recreate the feeling of watching an actual in-person talk. I will first cover parts, detailing what I got and some general suggestions, then I’ll discuss the filming process, and finally, I will cover the post-process procedure and software. The entire process took about a day and a half, with an overnight render, and cost about $200 (best compared to the cost of registration of a live conference).
The final result
You can watch the complete talk here:
If you are interested in the content of the talk, also see the PyHEP live presentation as well for an in-depth dive into boost-histogram, as well as the world-premiere demo of Hist.
Equipment
Due to COVID related shortages, parts were very limited and harder to obtain. Green screens, podcaster microphones, and tripods were all in very short supply.
Audio
The most important piece is a good microphone. Unless you have a excellent
microphone on your computer (such as a 2020 27" iMac or 16 inch MacBook Pro, if
you can manage to keep the fans off), you will really benefit from a standalone
microphone. For this recording, I got a Thronmax MDrill One Pro ($70), and was
pleasantly impressed. For just talk recordings, you probably could get a
Thronmax Pulse ($40) or a Samson Go ($50) for similar results. You just want a
nice mic, ideally a mountable condenser microphone. If you want to stand and
give your talk, you’ll benefit from a microphone stand, which allows you to
place your microphone in an ideal position (less than a meter from the sound
source is a good rule). I got an On-Stage Euro boom microphone stand ($20).
SciPy’s editors tremendously reduced the audio quality when they added the begin/end caps, so check the PyHEP live presentation for a better example of the microphone.

Figure 1: Raw footage as it was shot.
Video
For video, I used an old Canon T3 Rebel SLR, only capable of 720p and with a broken focus motor. Since the final video will be small, the camera is really not very important. The main requirements are a) not too close/wide (cropping a high res phone video would be fine, though), b) focus lock so you don’t refocus while filming, and c) manual color balance controls. If you get a phone tripod adaptor ($10-$20), you can use an app to fill the requirements on a modern smartphone. But the SLR did this just fine, as well (and modern SLRs even have podcast/video conference modes now!).
Another feature of the SLR was the external monitor support - I plugged it into a monitor and was able to monitor the recording. It is helpful to make sure your hands do not go outside the framing, and to get a rough idea of what your video looks like while recording, but is not required.
I originally ordered a Sony tripod ($30), which would have really helped, but due to COVID delays and stocking issues, it was replaced by a Magnus Video Tripod (~$50), which did not come in time. It would have been much easier, but since I didn’t have it, I placed the camera on an old broken table tripod, using books to prop up the missing leg.
Backdrop
For the green screen effect, you need either a green screen or a blue screen. I was very limited in my selection; I ended up with a massively long roll of paper green screen for an exorbitant price (~$50). I used masking tape to place it on a wall. It was a thick paper, but it still wrinkled easily, and the result was not ideal, though passable.
The most important aspect of setting up a green screen is the lighting; I used three household lamps for lighting, but if you can get nice diffuse lighting for the green screen and separate lighting for your subject (you), that would be better. The more consistent and uniform the green in the camera, the easier it is in post to produce a high quality effect. If you do it right, you can hold a glass of water (or wear glasses / have hair) and it will still look fantastic.
Remember to wear contrasting clothes; a green shirt will partially disappear into your green screen! Feel free to do a trial run, as well - I found that a black and white striped shirt had some issues with reflections, so I chose a blue shirt which was easier. You can manually animate a masking layer, but it is very time intensive for a longer clip (think roughly a minute per second or two), so spend a little time to get it right in camera!
Filming
Before filming, use a 50% grey card (or anything with a nice, neutral grey tone) to set your white balance; make sure it is set near where you will be standing, in the same lighting you will be under. This will save you from having to do color correction afterwards. Lock the focus on where you will be standing. Make sure you will stay inside the frame at all times (not counting edges that will be against the edge of the slide). Don’t worry if other objects or the green screen edges are in the frame - static or lightly animated masks are trivial.
Make sure the microphone is within a meter of your mouth, ideally half that. If you want to have it in frame, that’s a valid option that I have seen used. The Thronmax had colored lighting options (don’t match your screen, obviously!) if it had been in frame. A good microphone gives you quite a bit of leeway in amplifying the sound, though, so I chose to have it just out of the frame, and then scaled it up a bit in post.
I setup two separate recordings. The first was the camera, with low-quality audio and an external screen for live feedback. The second was my laptop, running Quicktime to record both the screen (more for the slide timing than for final output) and for the high quality audio.
After starting both recordings, clap. That will give you a point to sync to when you are replacing your low quality camera audio with the computer recording. You can use a professional style clapper instead, but clapping works just as well and is free.
During recording, try not to move around too much (the shadow effect does not work well if you move forward or backward unless you manually key it, which I did not do). I found it tricky to recover from mistakes - while transitions at slide boundaries are passable, it is still much harder than a pure audio recording to cut and splice. Also, the fewer mistakes you make, the less time you’ll have to spend in post rewatching and splicing. You likely will be doing long takes - I did 3-4 20 minute sessions, because that was the file size on the camera filesystem. It works best if you practice and treat it like a live talk - which I didn’t have time to do.
One note: you don’t have to have perfect slides at this point. If you overlap an element on the slides, you can edit them later in post rather easily - really only the slide transition timing is important at this stage.
Editing
The first issue I encountered in post was the video format from the screen recording - it was slightly off in aspect ratio and didn’t match the framerate of the camera. I used FFmpeg to match the frame rates and scale to improve performance when rendering. Quicktime (or Apple Screenshot, I think they share the same screen recording interface) records the screen at full resolution and 60 frames per second, which is a pain to blend with a 29.97 DSLR output. If you are using a Linux or Windows screen recording tool, you might be able to set it up correctly to start with. Here’s the exact FFMPEG command:
ffmpeg -i "Screen Recording 2020-06-11 at 3.17.53 PM.mov" -filter:v "fps=fps=29.97,crop=iw:ih-224,scale=1920:1080" Scaled.mov
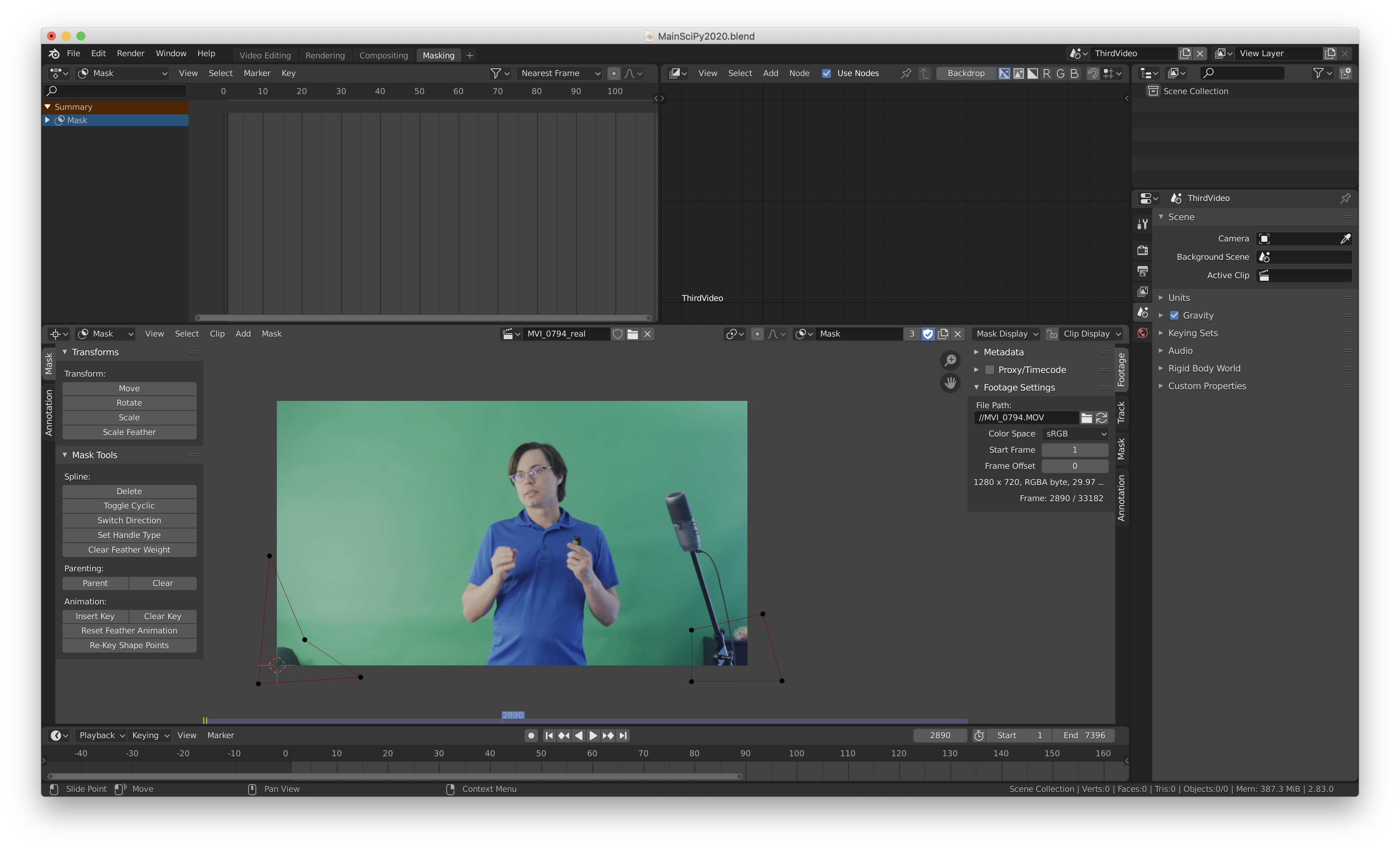
Figure 2: Raw footage in Blender. Masking is being applied to the corners to remove extra items.
I used Blender VSE to do the editing, and Blender’s node editor to build the more complicated part of the compositing and masking. The node setup I used is shown in Figure 3. I used a mask (Figure 2) to block out the extra stationary objects. I input a movie clip and the mask into the excellent Keying node. I adjusted the parameters there until I was happy with the key and despill. I then took the keyed mask, added a blur and an offset, converted to a lighter shade via a Multiply, and added it (with a clamp at 1) to the original keyed mask. This is the “shadow” layer. I took the keyed image and put it through a premul converter, which changes the “color” hidden by transparency to black. Then I used the shadow layer to set the alpha, creating the shadow.
I made a new linked Scene in Blender for each video input. I added the scenes into the VSE (next paragraph).
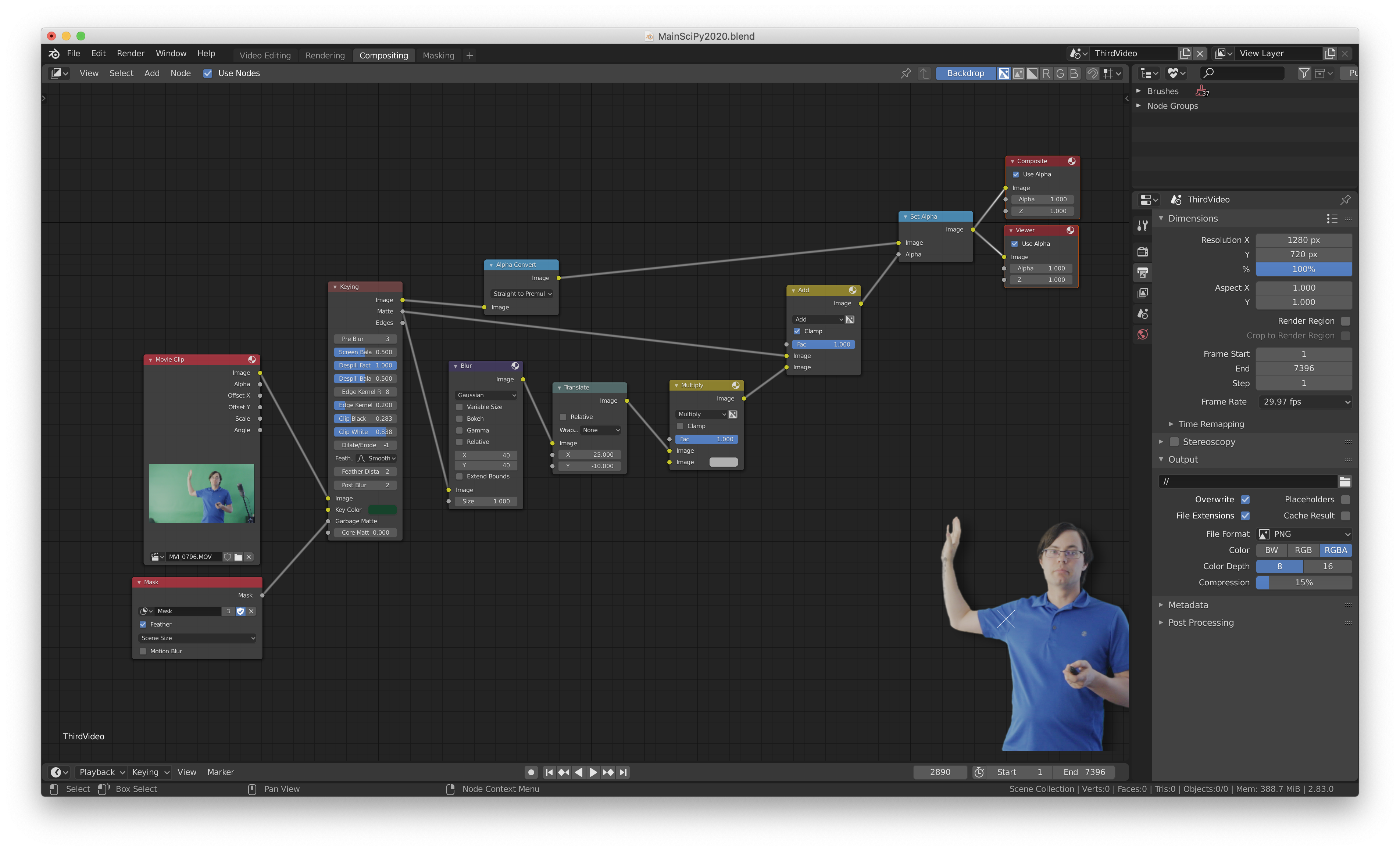
Figure 3: Blender node setup showing masking, chromakey, and shadow calculation.
To do the editing, I mostly used the Blender Video Sequence Editor (VSE). The VSE is great at snipping and stitching, at least once you get used to the odd blend of Blender and traditional VSE controls (neither of which are probably familiar to most people, and they are even weirder together). I ended up changing quite a few slides after-the-fact for better layout and then inserting them as pictures; it’s trivial to do the whole thing that way, actually, and have no screen recording if you just know when the transitions are - that’s the hard part of even just dropping in an image. The problem with Blender’s VSE is it doesn’t make good use of cores, so the 32 minute video took 7 hours to render and encode.
To start, I turned on the audio waveform display, and scaled up the audio to roughly match the clips, then aligned the waveforms on the clap. You should listen to the clap - it should sound like one clap, and not have an obvious echo effect. Then I separated the audio clips, and deleted the poor quality one. The clips should be stacked audio, background, empty track, then video. You can add a transform affect onto the video to place it into the corner of the video. Using a metastrip, you can group the clips together to make them easier to trim and move without risking misalignments. The empty track gives you a place to add individual stills of slides (trivial to produce en-mass from PDFs or Keynote, if you save as images). That allows you to replace the background. See Figure 4 for an example of a segment of video.
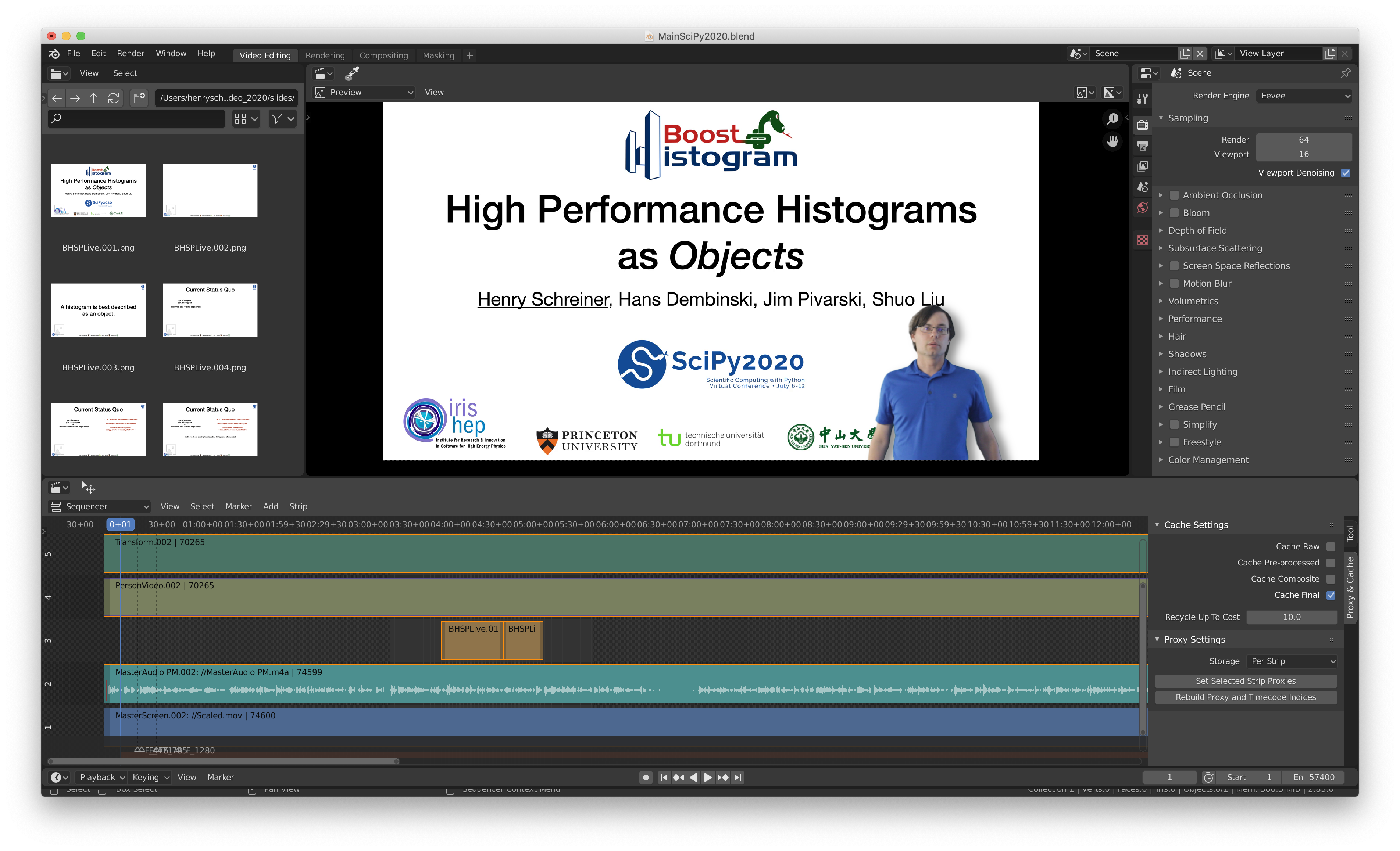
Figure 4: Blender VSE example.
For the output, I used FFMpeg H.264 via Quicktime container, High quality, good encoding speed, and AAC 192 audio. Framerate must match the input video, 29.97 fps for me. I did 1080p for the output (the camera video is smaller than the output, so you don’t need to match there).
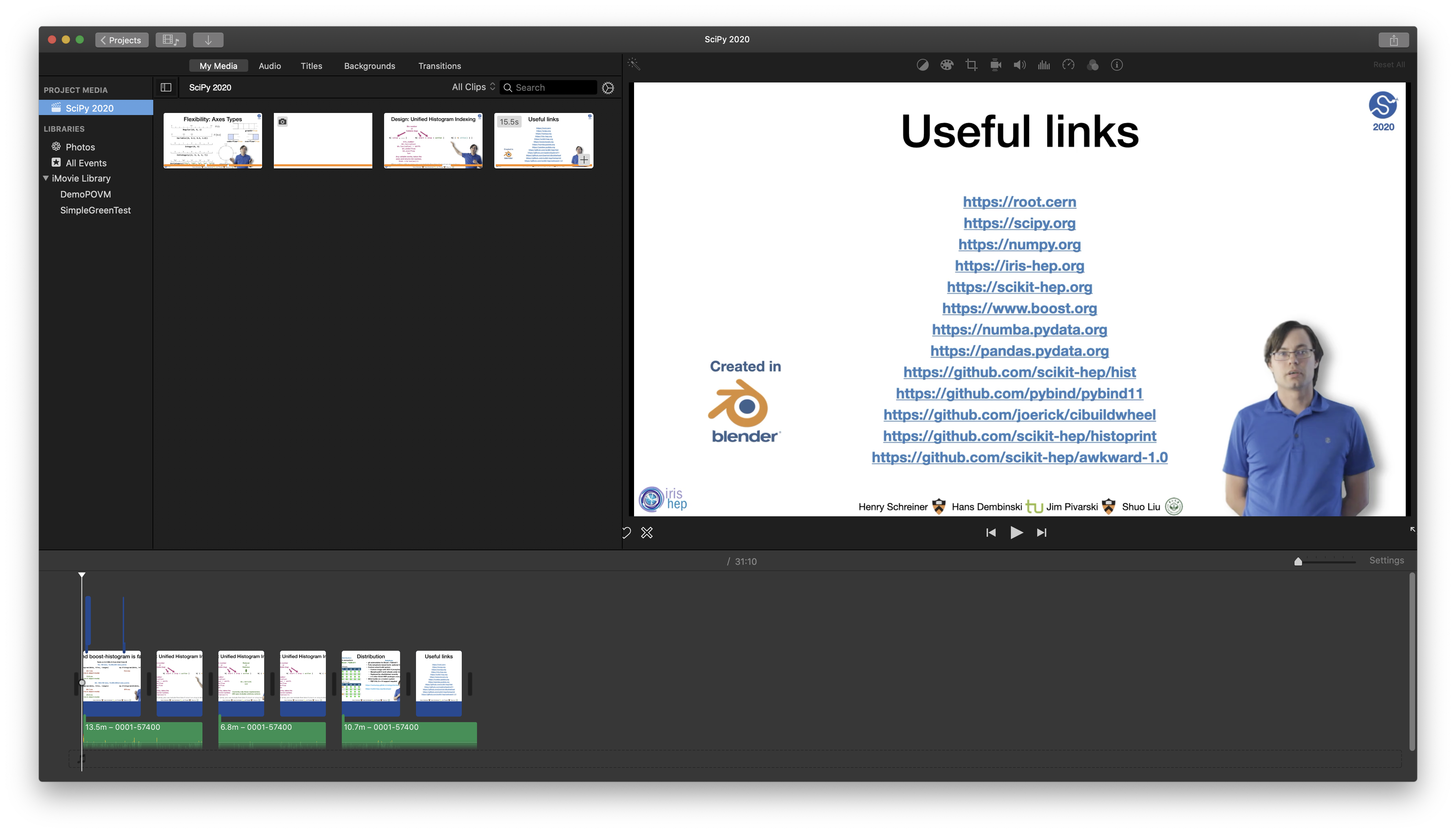
Figure 5: iMovie final cut example.
A small amount of further trimming was done in iMovie, as it could rerender in about 8 minutes (turning my 8-core MacBook into a portable griddle in the process) and time was running short, with a few final edits discovered after the final VSE render (Figure 5). Besides the final small trims, I also added a very small amount of noise suppression. This is not a fair performance comparison, since iMovie is not compositing, but really just re-encoding. The fact that iMovie was able to play the rendered video at full speed made it easy to do the final trimming and catch things that still needed to be removed. I also did a tiny bit of extra masking/replacement for a few slides that had minor issues still.
YouTube
Before or after uploading to YouTube (or other platforms), there are a few more things you can do to make your content more accessible and friendly.
Captioning
In the past, I’ve usually captioned by hand, but this time I submitted the final video (with endcaps) to Rev.com for captioning (~$50). They did a very good job, even catching the difference between Boost.Histogram and boost-histogram most of the time. I still need to do some polishing, however; there were a few errors, and occasionally what I said was not quite what I meant to say, so I corrected the text. I also wanted to adjust the timing of the captions slightly for better effect.
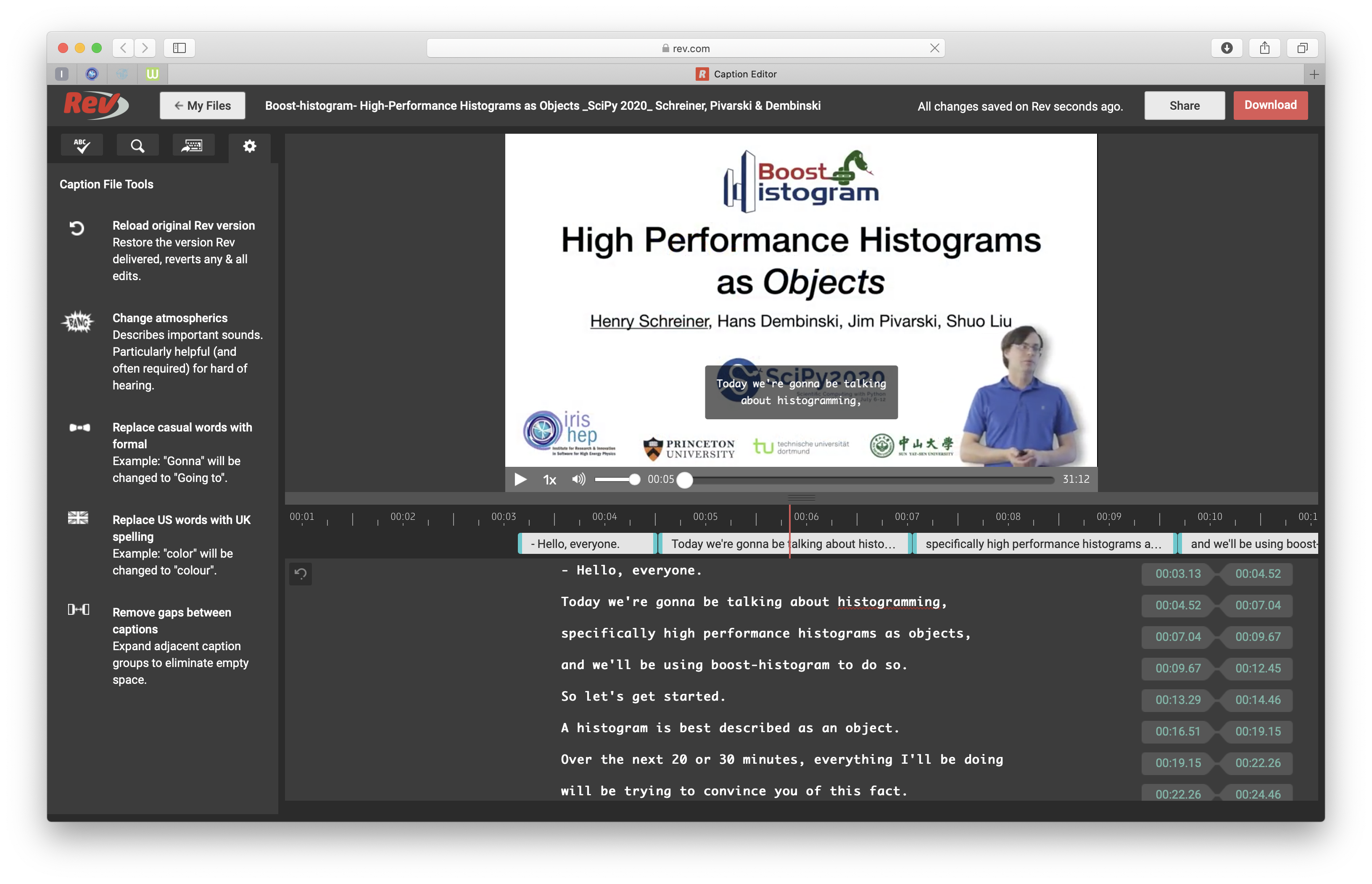
Figure 6: Rev caption polishing
The editor (Figure 6) was simple and powerful. There were several whole-file tools (far left) that I didn’t notice until after I was done that might have been useful. To edit, I just watched the video until I found a problem, and then paused. If it was a caption that needed changing, the captions can be changed in the bottom panel. If the timing was off, or there was a gap I wanted to fill in, you can drag the edges of the captions into place.
Once you are done, download the .srt file and upload it to YouTube.
Chapters
The final step was to add the chapters to the YouTube description. You just scan through the video, finding the breaking points between segments, recording the time for each. Then, when you are done, you should have something like this:
00:00 Intro
02:23 First chapter
17:32 Final chapter
You can use minute:second for short videos, or hour:minute:second for longer videos. When you add that to the description, it will automatically segment the video into chapters, and make scrubbing and navigation simple.
Conclusion
There were quite a few things I could have done better. Due to last minute work on the Princeton Open Ventilation Monitor, I was not able to spend as much time as I wanted in preparing the video; only about 1.5 days for filming and post-processing. Several ideas had to be removed - I was intending to have a little more interaction with the slides (such as walking off the frame when a slide needed to be filled up). I didn’t have time to rehearse, and I ended up moving around a little too much. But hopefully this was helpful, and will inspire more thought and innovation into giving informative and entertaining talks in a pre-recorded format!